
OpenAI obtient des résultats comparables à ceux d’un humain sur un test évaluant l’« intelligence générale » – décryptage

Un nouveau modèle d’intelligence artificielle (IA) vient d’obtenir des résultats comparables à ceux d’un humain lors d’un test conçu pour mesurer l’« intelligence générale » — des résultats bien meilleurs que les IA précédentes. Que sait-on précisément de cette avancée, et que signifie-t-elle ?
Le 20 décembre 2024, le système o3 d’OpenAI a obtenu 85 % au test de référence ARC-AGI, ce qui est nettement supérieur au meilleur résultat obtenu par l’IA précédente (55 %) et équivalent aux résultats humains moyens. o3 a également obtenu de bons résultats à un test de mathématiques très difficile.
Créer une intelligence artificielle « générale » est l’objectif déclaré de tous les grands laboratoires de recherche sur l’IA. L’annonce récente d’OpenAI semble indiquer que l’entreprise vient d’accomplir une prouesse dans cette direction. (ndlt : L’abréviation francophone d’« intelligence artificielle générale » est « IAG » mais ce sigle est parfois utilisé pour parler d’intelligence artificielle générative, qui est une famille particulière de systèmes d’intelligence artificielle, exploitant notamment l’apprentissage profond, et dont ChatGPT est le membre le plus médiatique.)
Même si un certain scepticisme est de mise, de nombreux chercheurs et développeurs en IA ont le sentiment que les lignes sont en train de bouger : la possibilité d’une intelligence artificielle générale semble plus tangible, plus actuelle qu’ils et elles ne le pensaient jusqu’à présent. Qu’en est-il ? Tentons de décrypter cette annonce.
Généralisation et intelligence artificielle
Pour comprendre ce que signifie le résultat obtenu par o3 d’OpenAI, il faut se pencher sur la nature du test ARC-AGI qu’o3 a passé.
Il s’agit d’un test évaluant la « sample efficiency » d’un système d’IA (ndlt : parfois traduit par « efficacité en données »), c’est-à-dire sa capacité à s’adapter une situation nouvelle, ou, en termes plus techniques, la capacité d’un modèle de machine learning à obtenir des bonnes performances avec un apprentissage basé sur peu de données.
En effet, l’apprentissage de ces modèles est normalement basé sur de très grands ensembles de données, ce qui les rend coûteux à entraîner. Un système d’IA comme ChatGPT (GPT-4) n’est pas très « efficace en données » : il a été entraîné sur des millions d’exemples de textes humains, d’où il a tiré des règles probabilistes qui lui dictent les suites les plus probables de mots. Cette méthode est efficace pour générer des textes généralistes ou d’autres tâches « courantes » ; mais dans le cas de tâches peu courantes ou plus spécialisées, le système est moins performant car il dispose de peu de données pour chacune de ces tâches.
Tant que les systèmes d’IA ne pourront pas apprendre à partir d’un petit nombre d’exemples (d’un petit ensemble de données) — c’est-à-dire démontrer une certaine « efficacité en données » —, ils ne pourront pas s’adapter aux situations plus rares, ils ne seront utilisés que pour les tâches très répétitives et celles pour lesquelles un échec occasionnel est tolérable.
La capacité à résoudre avec précision des problèmes inconnus ou nouveaux à partir de peu de données s’appelle la « capacité de généralisation ». Elle est considérée comme un élément nécessaire, voire fondamental, de l’intelligence.
Grilles et motifs
C’est pour cela que le test de référence ARC-AGI, qui évalue l’intelligence « générale », utilise de petits problèmes de grilles comme celui présenté ci-dessous. À partir d’un nombre très restreint d’exemples, la personne ou l’IA testée doit trouver le modèle qui transforme la grille de gauche en la grille de droite. C’est bien l’« efficacité en données » qui est évaluée ici.
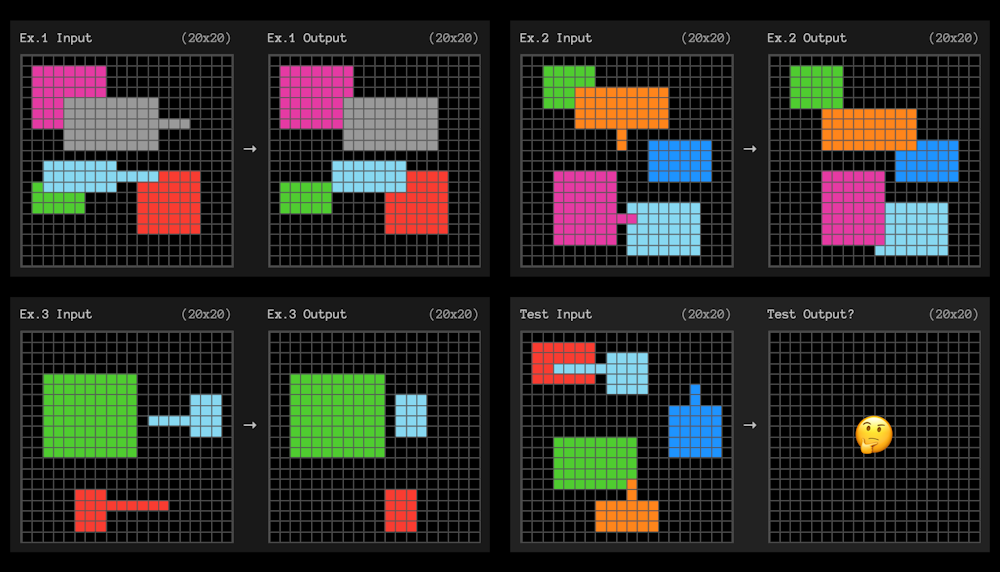{kind=link}
Chaque exercice commence par fournir trois exemples, desquels il faut extraire des règles, qui « généralisent » les trois exemples… et permettent de résoudre le quatrième.
Cela ressemble beaucoup à des tests de QI.
Trouver les règles nécessaires et suffisantes pour s’adapter
Nous ne savons pas exactement comment OpenAI a procédé, mais les résultats mêmes du test suggèrent que le modèle o3 est très adaptable : à partir de quelques exemples seulement, il a trouvé des règles généralisables qui lui ont permis de résoudre les exercices.
Pour s’attaquer à ce type d’exercice, il faut trouver les règles nécessaires et suffisantes pour résoudre l’exercice, mais ne pas s’infliger de règles supplémentaires, qui seraient à la fois inutiles et contraignantes. On peut démontrer mathématiquement que ces règles minimales sont la clef pour maximiser sa capacité d’adaptation à de nouvelles situations.
Qu’entendons-nous par « règles minimales » ? La définition technique est compliquée, mais les règles minimales sont généralement celles qui peuvent être décrites dans des énoncés plus simples.
Dans l’exemple ci-dessus, la règle pourrait être exprimée ainsi : « Toute forme comportant une ligne saillante se déplacera jusqu’à l’extrémité de cette ligne et recouvrira toutes les autres formes avec lesquelles elle se chevauchera dans sa nouvelle position ».
Recherche de chaînes de pensée ?
Bien que nous ne sachions pas encore comment OpenAI est parvenu à ce résultat, il semble peu probable que les ingénieurs aient délibérément optimisé le système o3 pour trouver des règles minimales — mais o3 a bien dû trouver ces règles.
Nous savons qu’OpenAI a commencé par leur version générique du modèle o3 (qui diffère de la plupart des autres grands modèles de langage, car il peut passer plus de temps à « réfléchir » à des questions difficiles) et l’a ensuite entraîné spécifiquement pour passer le test ARC-AGI.
Le chercheur français en IA François Chollet, qui a conçu le test de référence (ndlt : et qui travaillait chez Google jusqu’à récemment), estime qu’o3 recherche différentes « chaînes de pensée » décrivant les étapes à suivre pour résoudre la tâche. (ndlt : Une « chaîne de pensée » est une stratégie exploitée en IA, qui mimique une stratégie humaine consistant à décomposer un problème complexe en petites unités plus simples, amenant pas à pas à une solution globale.)
o3 choisirait ensuite la « meilleure » chaîne de pensée en fonction d’une règle définie de façon relativement pragmatique et vague, dans une approche « heuristique ».
Cette stratégie ne serait pas très différente de celle utilisée par le système AlphaGo de Google pour chercher différentes séquences de mouvements possibles à même de battre le champion du monde de go en 2016.
On peut considérer ces chaînes de pensée comme des programmes qui sont adaptés aux exemples et permettent de les résoudre. Bien sûr, si o3 exploite bien une méthode similaire à celle utilisée dans AlphaGo, il a fallu fournir à o3 une heuristique, ou règle souple, pour lui permettre de déterminer quel programme était le meilleur. Car des milliers de programmes différents, apparemment aussi valables les uns que les autres, pourraient être générés pour tenter de résoudre les trois exemples. On pourrait imaginer une heuristique qui « sélectionne le programme minimal » ou bien qui « sélectionne le programme le plus simple ».
Toutefois, s’il s’agit d’un mécanisme similaire à celui d’AlphaGo, il suffit de demander à une IA de créer une heuristique. C’est ce qui s’est passé pour AlphaGo : Google a entraîné un modèle à évaluer différentes séquences de mouvements comme étant meilleures ou pires que d’autres.
Ce que nous ne savons toujours pas
La question qui se pose donc est la suivante : est-on vraiment plus proche de l’intelligence artificielle générale ? Si o3 fonctionne comme on vient de le décrire, le modèle sous-jacent n’est peut-être pas beaucoup plus performant que les modèles précédents.
Les concepts que le modèle apprend de données textuelles (ou plus généralement du langage humain) ne permettent peut-être pas davantage de généralisation qu’auparavant. Au lieu de cela, nous pourrions simplement être en présence d’une « chaîne de pensée » plus généralisable, découverte grâce aux étapes supplémentaires d’entraînement d’une heuristique spécialisée pour le test en question aujourd’hui.
On y verra plus clair, comme toujours, avec davantage de recul et d’expérience autour de o3.
En effet, on ignore presque tout au sujet de ce système : OpenAI a fait des présentations aux médias assez limitées, et les premiers tests ont été réservés à une poignée de chercheurs, de laboratoires et d’institutions spécialisées dans la sécurité de l’IA.
Pour évaluer le véritable potentiel d’o3, il va falloir un travail approfondi, notamment pour déterminer à quelle fréquence il échoue et réussit.
C’est seulement quand o3 sera réellement rendu public que nous saurons s’il est à peu près aussi adaptable qu’un humain moyen.
Si c’est le cas, il pourrait avoir un impact économique énorme et révolutionnaire, et ouvrir la voie à une nouvelle ère d’intelligence artificielle, capable de s’améliorer d’elle-même. Nous aurons besoin de nouveaux critères pour évaluer l’intelligence artificielle générale elle-même, et d’une réflexion sérieuse sur la manière dont elle devrait être gouvernée.
Si ce n’est pas le cas, o3 et son résultat au test ARC-AGI resteront un résultat impressionnant, mais nos vies quotidiennes resteront sensiblement les mêmes.
Michael Timothy Bennett, PhD Student, School of Computing, Australian National University et Elija Perrier, Research Fellow, Stanford Center for Responsible Quantum Technology, Stanford University
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.